Reuso de Bitácora y Dimensiones Aeronáuticas
A continuación, se presentan ejemplos de cómo reutilizar los datos de la bitácora de operaciones (Parquet) en conjunto con los archivos de dimensiones aeronáuticas (CSV) desde la URL de publicación o desde un archivo descargado. Esto, en diversos lenguajes de programación o aplicaciones de inteligencia de negocios.
¿Qué es el Formato Parquet?
La bitácora de operaciones se encuentra disponible en Parquet, un formato de almacenamiento de datos orientado a columnas, optimizado para el análisis de datos. Este formato permite trabajar con grandes volúmenes de datos, utilizando un esquema de compresión eficiente reduciendo el espacio de almacenamiento requerido. Son por estos motivos que se escogió Parquet para la publicación de la bitácora de operaciones.
¿Cómo Reutilizar los Datos?
Dependiendo del lenguaje de programación o aplicación de inteligencia de negocios que se utilice, los archivos, en Parquet o CSV, pueden ser descargados o utilizados directamente desde la URL de publicación.
A continuación, se describe la forma de descargar y reutilizar los archivos.
Descarga de Archivos
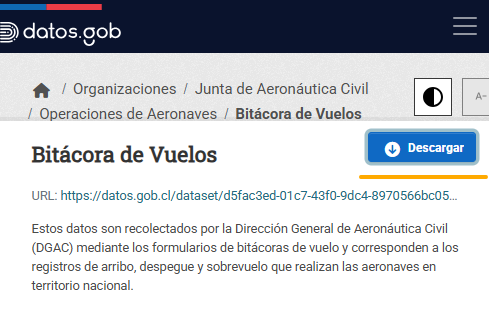
Los archivos de bitácora de operaciones y dimensiones aeronáuticas pueden ser descargados directamente desde el sitio web de Datos.Gob presionando en "Descargar":
Por otra parte, la URL de publicación se encuentra disponible en el mismo sitio web, donde se puede copiar el enlace:
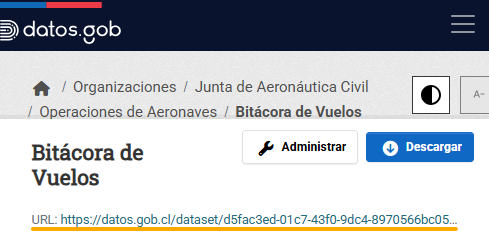
Por motivos de seguridad, el servidor de datos de la URL de publicación puede requerir más de un intento de carga cuando es utilizado mediante un script o aplicación.
Herramientas para Reutilizar los Datos
A continuación, se presentan ejemplos de cómo reutilizar los datos de la bitácora de operaciones en diversos lenguajes de programación o aplicaciones de inteligencia de negocios.
Se asume un conocimiento básico de cada uno de los lenguajes o aplicaciones.
- Excel
- PowerBI
- Python
- SQL
- R
Excel permite un máximo de 1.048.576 filas por hoja, mientras que el archivo parquet de bitácora (a abril de 2025) contiene más de 10 millones, por lo que se recomienda utilizar un subconjunto de datos o una herramienta diferente de análisis de datos. Por ejemplo PowerBI, Python, SQL, R, entre otras.
Excel no permite cargar archivos Parquet directamente, sin embargo, existen varias opciones para transformarlos con la finalidad de ser utilizados en la aplicacion de Office:
-
Utilizar Parquet Viewer para abrir el archivo Parquet y luego exportar a CSV:
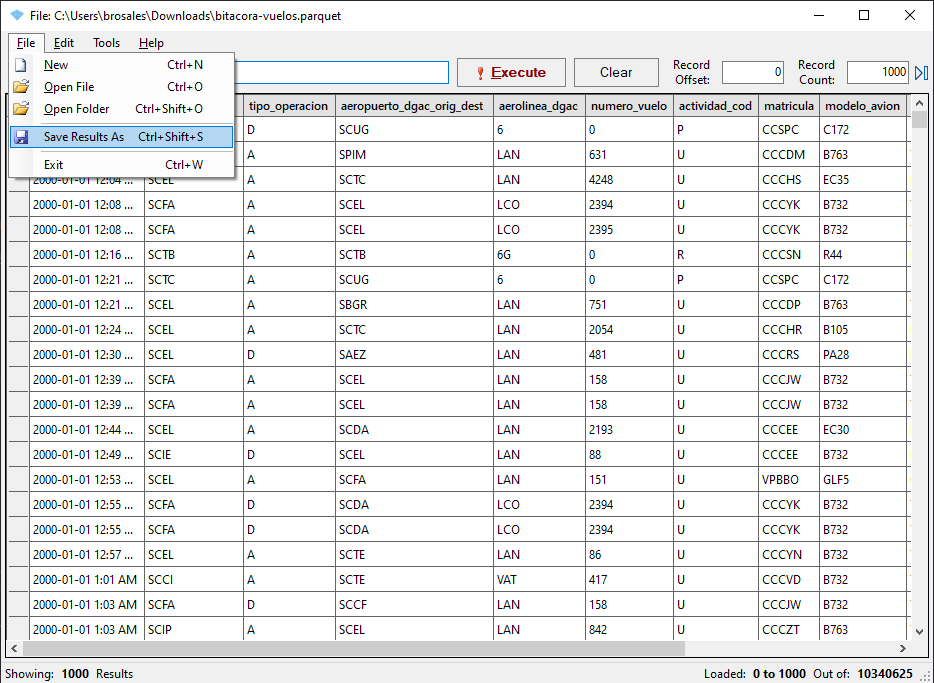
ParquetViewer permite seleccionar solo un subconjunto de datos, utilizando la sección de Filter Query.
-
La última versión de DuckDB permite abrir archivos Parquet y exportarlos Excel.
INSTALL excel;
LOAD excel;
COPY (
FROM 'C:\path\a\bitacora-vuelos.parquet' -- MacOS y Linux: '/path/a/bitacora-vuelos.parquet'
WHERE YEAR(dt_operacion) > 2024
) TO
'C:\path\a\resultado\bitacora-vuelos.xslx'
WITH (FORMAT xlsx, HEADER true)
;Más información sobre como utilizar DuckDB como herramienta de carga y análisis de datos de la bitácora, revisar la pestaña "SQL".
-
PowerBI permite cargar archivos Parquet (ver siguiente pestaña) y exportarlos a CSV presionando el botón "Export Data" en una visualización:
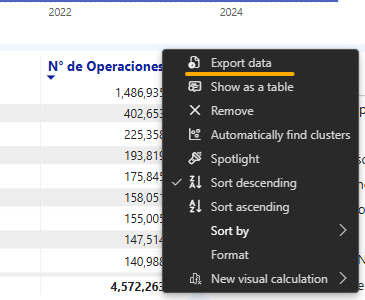
Haciendo click derecho sobre la tabla de datos y seleccionando la opción copiar.
Finalmente, en la vista de tablas, se puede hacer click derecho sobre los datos y seleccionar la opción "Copiar" valor, columna o tabla completa para luego ser pegada en Excel:
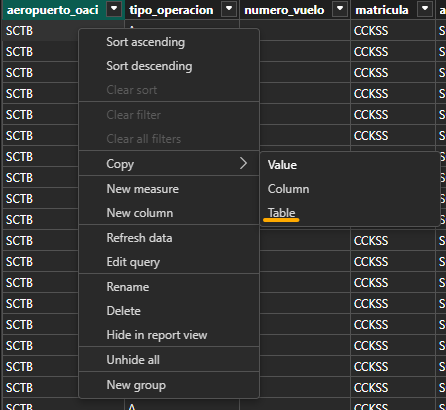
-
Herramientas de programación como Python, R o SQL permiten cargar archivos Parquet y exportarlos a CSV o Excel. Revisar las pestañas correspondientes para más información.
Si presenta problemas al abrir el archivo CSV en Excel, se recomienda abrirlo mediante la opción "De texto/CSV" en la pestaña "Datos" de Excel:
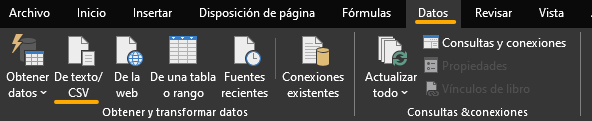
Para cargar el archivo Parquet en PowerBI, se debe seleccionar el botón "Obtener Datos":

Luego seleccionar la opción "Parquet":
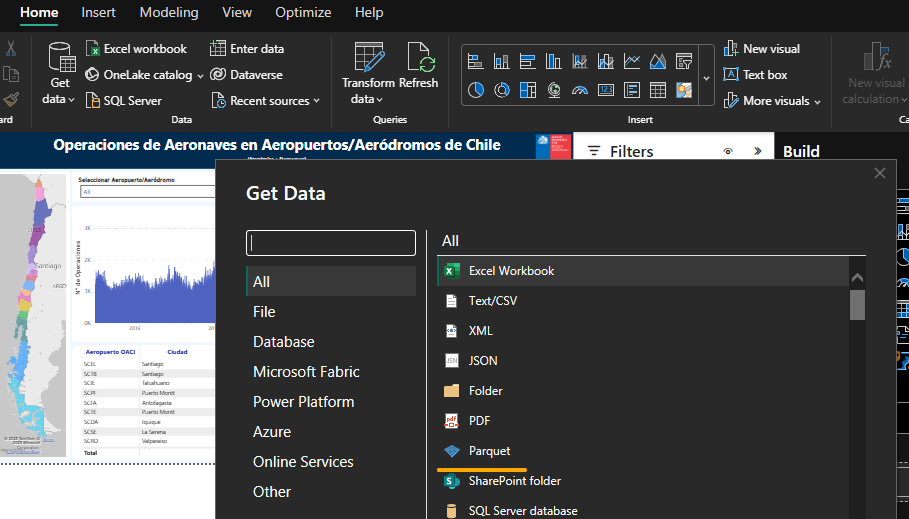
PowerBI permite cargar un archivo Parquet desde la URL de publicación o desde una ruta local, sin embargo, para archivos de mayor volumen es recomendado descargar el archivo a una ruta local, en este caso desde el sitio web de Datos.Gob:
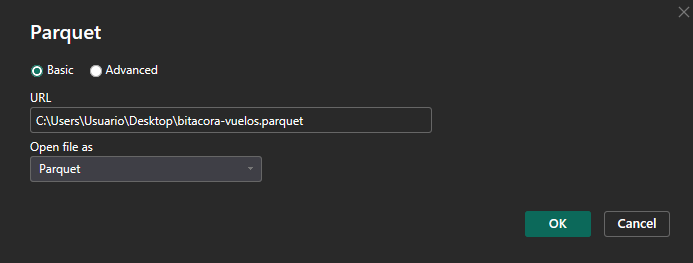
Luego, se debería observar el dataset de bitácora disponible para ser cargado o transformado en PowerQuery:
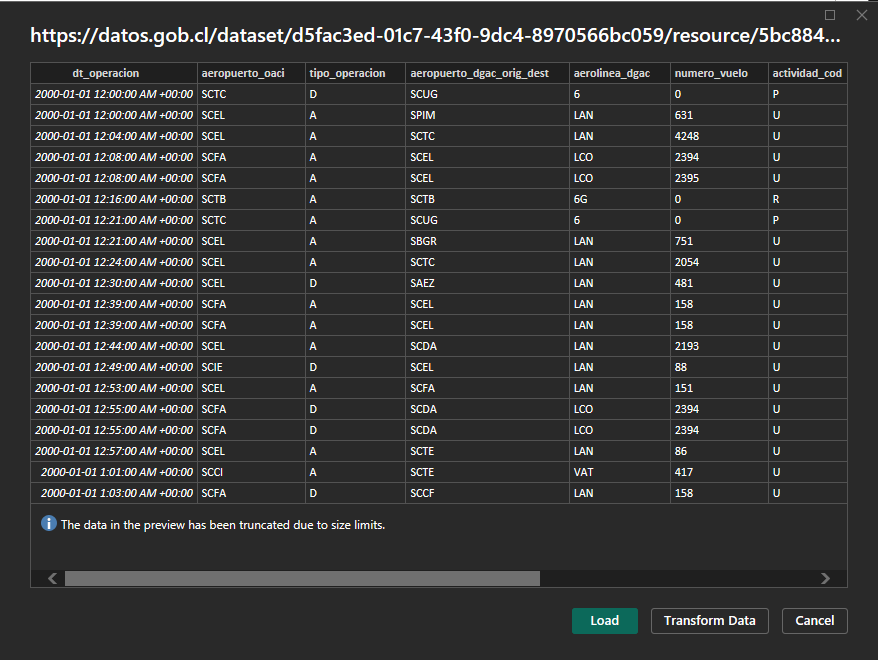
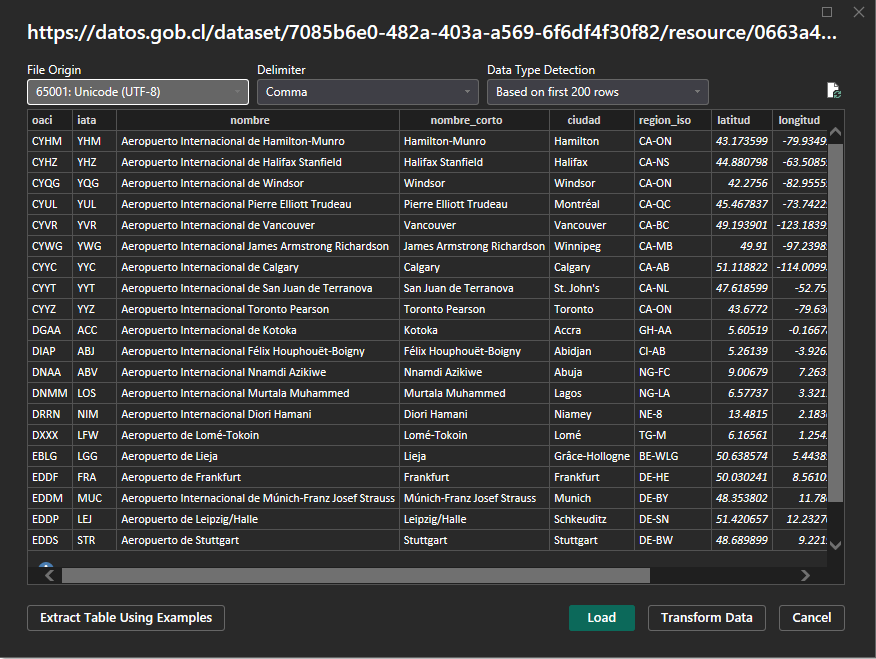
PowerBI permite utilizar archivos CSV de la misma forma, por ejemplo con la dimensión de aeropuertos:
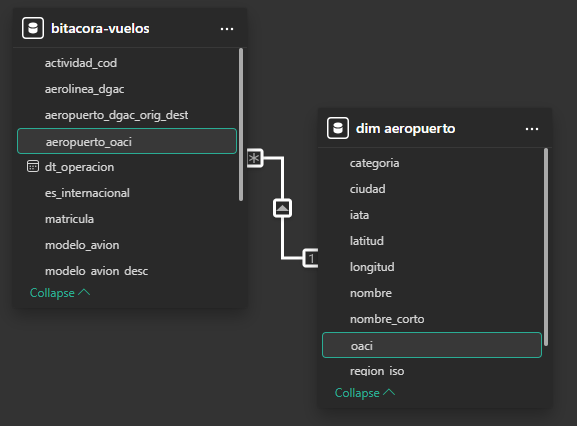
Con estas dos tablas es posible generar una relación entre ambas:
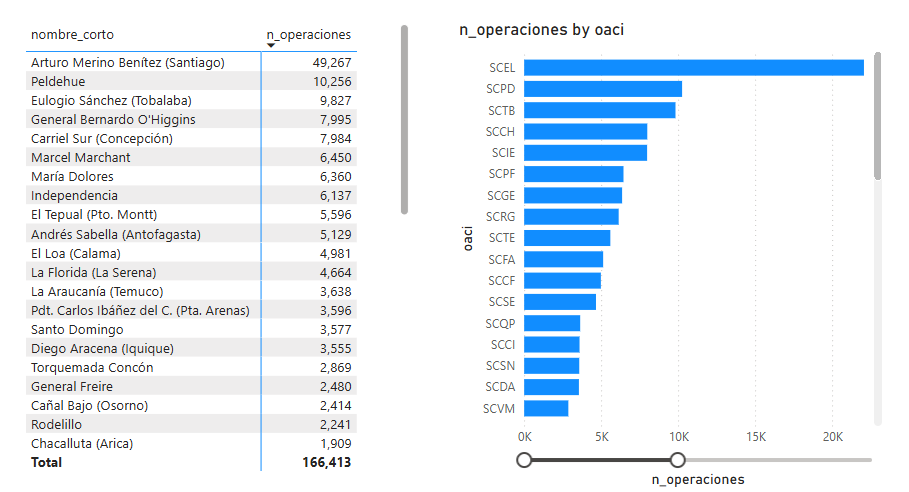
Finalmente, se puede calcular la cantidad de operaciones por aeropuerto:
Para cargar el archivo Parquet en Python, se pueden utilizar librerías
como Pandas, Polars o
DuckDB, entre otras, para lo que
se recomienda crear un ambiente virtual primero, por ejemplo, con venv
o uv (este último es la opción recomendada).
A continuación, se muestran ejemplos con las librerías de Pandas y Polars.
- Pandas
- Polars
Para que el código funcione, es necesario instalar las librerías de pandas y pyarrow
pip install pandas pyarrow
# o con uv.
uv add pandas pyarrow
Luego, se pueden realizar operaciones sobre los datos de la siguiente forma:
from datetime import datetime
import pandas as pd
import pytz
URL_DGOB_BITACORA = (
"https://datos.gob.cl/dataset/d5fac3ed-01c7-43f0-9dc4-8970566bc059/"
"resource/5bc8842e-d95a-4f8f-8ec6-acfbe700258a/download/bitacora-vuelos.parquet"
)
URL_DGOB_DIM_AEROP = (
"https://datos.gob.cl/dataset/7085b6e0-482a-403a-a569-6f6df4f30f82/"
"resource/0663a4e0-c224-4ca9-98de-dfa7ec57bdbd/download/dim.aeropuerto.csv"
)
# En caso de no querer leer el archivo completo a memoria, utilizar el argumento "filters"
# para optimizar la lectura del parquet.
operaciones = pd.read_parquet(
URL_DGOB_BITACORA,
filters=[("dt_operacion", ">=", datetime(2025,1,1, tzinfo=pytz.UTC))] # Operaciones del 2025 en adelante.
)
# Leer la dimensión de aeropuerto a
dim_aeropuerto = pd.read_csv(URL_DGOB_DIM_AEROP)
# Para unir la dimensión
operaciones = operaciones.merge(dim_aeropuerto, left_on="aeropuerto_oaci", right_on="oaci")
# Contar operaciones por aeropuerto.
(
operaciones["aeropuerto_oaci"]
.groupby([operaciones["aeropuerto_oaci"], operaciones["nombre_corto"]])
.count()
.sort_values(ascending=False)
)
Para que el código funcione, es necesario instalar las librerías de polars y pytz
pip install polars pytz
# o con uv.
uv add polars pytz
Luego, se pueden realizar operaciones sobre los datos de la siguiente forma:
from datetime import datetime
import polars as pl
import pytz
URL_DGOB_BITACORA = (
"https://datos.gob.cl/dataset/d5fac3ed-01c7-43f0-9dc4-8970566bc059/"
"resource/5bc8842e-d95a-4f8f-8ec6-acfbe700258a/download/bitacora-vuelos.parquet"
)
URL_DGOB_DIM_AEROP = (
"https://datos.gob.cl/dataset/7085b6e0-482a-403a-a569-6f6df4f30f82/"
"resource/0663a4e0-c224-4ca9-98de-dfa7ec57bdbd/download/dim.aeropuerto.csv"
)
# Definir la operación de carga de los datos con un LazyFrame.
lazy_ops = (
pl.scan_parquet(URL_DGOB_BITACORA)
.filter(
pl.col("dt_operacion").dt.convert_time_zone("UTC") >= datetime(2025, 1, 1, tzinfo=pytz.UTC)
)
)
# Dimensiones.
dim_aeropuerto = pl.scan_csv(URL_DGOB_DIM_AEROP)
# Contar operaciones por aeropuerto.
(
lazy_ops
.join(dim_aeropuerto, left_on="aeropuerto_oaci", right_on="oaci", how="inner")
.group_by(["aeropuerto_oaci", "nombre_corto"])
.agg(pl.len().alias("n_operaciones"))
.sort("n_operaciones", descending=True)
).collect()
Utilizando DuckDB, es posible trabajar los datos directamente desde la URL a través de SQL. Teniendo instalado este programa, en conjunto con una aplicación de análisis de datos como JupyterLab o DBeaver se puede manipular el archivo.
A continuación se presenta un ejemplo de cómo cargar el archivo Parquet en conjunto con los archivos de dimensiones aeronáuticas (CSV) desde la URL de publicación:
CREATE OR REPLACE TABLE main.bitacora_dgac AS
FROM
'https://datos.gob.cl/dataset/d5fac3ed-01c7-43f0-9dc4-8970566bc059/resource/5bc8842e-d95a-4f8f-8ec6-acfbe700258a/download/bitacora-vuelos.parquet' bd
-- Opcion alternativa desde una ruta en el computador.
-- 'C:\ruta\al\archivo\bitacora-vuelos.parquet'
WHERE
bd.dt_operacion >= TIMESTAMP '2025-01-01' -- Opcional
;
CREATE OR REPLACE TABLE main.dim_aeropuerto AS
FROM
'https://datos.gob.cl/dataset/7085b6e0-482a-403a-a569-6f6df4f30f82/resource/0663a4e0-c224-4ca9-98de-dfa7ec57bdbd/download/dim.aeropuerto.csv'
;
CREATE OR REPLACE TABLE main.dim_aerolinea AS
FROM
'https://datos.gob.cl/dataset/7085b6e0-482a-403a-a569-6f6df4f30f82/resource/4d3c30d3-a7e1-40ef-9ec3-1af6a7b5164c/download/dim.aerolinea.csv'
;
CREATE OR REPLACE TABLE main.dim_actividad AS
FROM
'https://datos.gob.cl/dataset/7085b6e0-482a-403a-a569-6f6df4f30f82/resource/ca67dae0-8b11-49a5-b2d4-8cca5bc2ca4b/download/dim.actividad_dgac.csv'
;
Luego, es posible unir todas las tablas de la siguiente forma:
SELECT
bd.*
,da.descripcion AS actividad
,dp.nombre_corto AS aeropuerto_desc
,dpod.nombre_corto AS aeropuerto_orig_dest_desc
,dl.nombre AS nombre_aerolinea
FROM
main.bitacora_dgac bd
JOIN main.dim_actividad da ON da.codigo = bd.actividad_cod
LEFT JOIN main.dim_aeropuerto dp ON dp.oaci = bd.aeropuerto_oaci
LEFT JOIN main.dim_aerolinea dl ON dl.oaci = bd.aerolinea_dgac
LEFT JOIN main.dim_aeropuerto dpod ON dpod.oaci = bd.aeropuerto_dgac_orig_dest
ORDER BY
bd.dt_operacion
LIMIT 10
;
Finalmente, es posible contar las operaciones por aeropuerto:
SELECT
bd.aeropuerto_oaci
,dp.nombre_corto AS aeropuerto_desc
,COUNT(*) AS n_operaciones
FROM
main.bitacora_dgac bd
JOIN main.dim_actividad da ON da.codigo = bd.actividad_cod
LEFT JOIN main.dim_aeropuerto dp ON dp.oaci = bd.aeropuerto_oaci
LEFT JOIN main.dim_aerolinea dl ON dl.oaci = bd.aerolinea_dgac
LEFT JOIN main.dim_aeropuerto dpod ON dpod.oaci = bd.aeropuerto_dgac_orig_dest
GROUP BY ALL
ORDER BY
n_operaciones DESC
;
Es recomendado tener instalado renv para crear un ambiente
virtual en R. Luego, para instalar las librerías necesarias, se puede utilizar el siguiente código:
install.packages(c("lubridate", "tidyverse", "arrow"))
Finalmente, teniendo las librerías instaladas, se pueden realizar operaciones sobre los datos de la siguiente forma:
# Ruta a archivo parquet. Cambiar!
PATH_DGOB_BITACORA <- "path/a/bitacora-vuelos.parquet"
URL_DGOB_DIM_AEROP <- paste0(
"https://datos.gob.cl/dataset/7085b6e0-482a-403a-a569-6f6df4f30f82/",
"resource/0663a4e0-c224-4ca9-98de-dfa7ec57bdbd/download/dim.aeropuerto.csv"
)
# Lectura del archivo parquet desde una ruta.
operaciones <- arrow::open_dataset(PATH_DGOB_BITACORA) |>
dplyr::filter(dt_operacion >= as.POSIXct("2025-01-01", tz = "UTC")) |>
dplyr::collect()
# Dimensión de aeropuerto.
dim_aeropuerto <- readr::read_csv(URL_DGOB_DIM_AEROP)
# Joining de bitacora con dimensión de aeropuertos
operaciones <- merge(operaciones, dim_aeropuerto, by.x = "aeropuerto_oaci", by.y = "oaci")
# Counting operations by airport and sorting
operaciones |>
dplyr::group_by(aeropuerto_oaci, nombre_corto) |>
dplyr::summarise(count = dplyr::n(), .groups = "drop") |>
dplyr::arrange(desc(count))